In this post, I’ll show how to fetch stats for entities from the Nutanix v4 API using the Python SDK and explain how to put together a script with arguments that can produce dynamic graphs and csv exports of the retrieved data.
Extracting metrics from the Nutanix v4 API has changed quite a bit. In previous API versions, metrics would often be part of the entity payload and would include last values.
If you wanted to extract metrics for a specific time range, entity types had a stats endpoint you could use with parameters to do that.
In v4, the process to extract metrics for entities is the following:
- You initialize an API client for the
ntnx_aiops_py_clientSDK module, - You fetch the available sources uuids from
StatsApiusing theget_sources_v4function, - You fetch entity type names and uuids from
StatsApiusing theget_entity_types_v4function and the source uuid you want, - You fetch available metrics for each entity type from
StatsApiusing theget_entity_descriptors_v4function and the source uuid you want.
At this stage, you know which metrics are available for which entity types.
Next, you’ll need to initialize an API client for the module that contains actual stats for the entity you are interested in.
This table shows which module and which stats endpoints are available in the v4 API at the time of writing:
| module | namespace | endpoint | description | method |
|---|---|---|---|---|
| ntnx_vmm_py_client | vmm | vmm/v4.0/ahv/stats/vms | List VM stats for all VMs. Users can fetch the stats by specifying the following params in the request query: 1) ‘$select’: comma-separated attributes with the prefix ‘stats/’, e.g. ‘stats/controllerNumIo,stats/hypervisorNumIo’. 2) ‘$startTime’: the start time for which stats should be reported, e.g. ‘2023-01-01T12:00:00.000-08:00’; 3) ‘$endTime’: the end time for which stats should be reported; 4) ‘$samplingInterval’: the sampling interval in seconds at which statistical data should be collected; 5) ‘$statType’: the down-sampling operator to use while performing down-sampling on stats data; 6) ‘$orderby’; 7) ‘$page’; 8) ‘$limit’; and 9) ‘$filter’: the OData filter to use, e.g. ‘stats/hypervisorCpuUsagePpm gt 100000 and stats/guestMemoryUsagePpm lt 2000000.’ | GET |
| ntnx_vmm_py_client | vmm | vmm/v4.0/ahv/stats/vms/:extId | Get VM stats for a given VM. Users can fetch the stats by specifying the following params in the request query: 1) ‘$select’: comma-separated attributes with the prefix ‘stats/’, e.g. ‘stats/checkScore’. 2) ‘$startTime’: the start time for which stats should be reported, e.g. ‘2023-01-01T12:00:00.000-08:00’; 3) ‘$endTime’: the end time for which stats should be reported; 4) ‘$samplingInterval’: the sampling interval in seconds at which statistical data should be collected; 5) ‘$statType’: the down-sampling operator to use while performing down-sampling on stats data | GET |
| ntnx_vmm_py_client | vmm | vmm/v4.0/ahv/stats/vms/:vmExtId/disks/:extId | Fetches the stats for the specified VM disk. Users can fetch the stats by specifying the following params in the request query: 1) ‘$select’: comma-separated attributes with the prefix ‘stats/’, e.g. ‘stats/checkScore’. 2) ‘$startTime’: the start time for which stats should be reported, e.g. ‘2023-01-01T12:00:00.000-08:00’; 3) ‘$endTime’: the end time for which stats should be reported; 4) ‘$samplingInterval’: the sampling interval in seconds at which statistical data should be collected; 5) ‘$statType’: the down-sampling operator to use while performing down-sampling on stats data | GET |
| ntnx_vmm_py_client | vmm | vmm/v4.0/ahv/stats/vms/:vmExtId/nics/:extId | Fetches the stats for the specified VM NIC. Users can fetch the stats by specifying the following params in the request query: 1) ‘$select’: comma-separated attributes with the prefix ‘stats/’, e.g. ‘stats/checkScore’. 2) ‘$startTime’: the start time for which stats should be reported, e.g. ‘2023-01-01T12:00:00.000-08:00’; 3) ‘$endTime’: the end time for which stats should be reported; 4) ‘$samplingInterval’: the sampling interval in seconds at which statistical data should be collected; 5) ‘$statType’: the down-sampling operator to use while performing down-sampling on stats data | GET |
| ntnx_vmm_py_client | vmm | vmm/v4.0/esxi/stats/vms | List VM stats for all VMs. Users can fetch the stats by specifying the following params in the request query: 1) ‘$select’: comma-separated attributes with the prefix ‘stats/’, e.g. ‘stats/controllerNumIo,stats/hypervisorNumIo’. 2) ‘$startTime’: the start time for which stats should be reported, e.g. ‘2023-01-01T12:00:00.000-08:00’; 3) ‘$endTime’: the end time for which stats should be reported; 4) ‘$samplingInterval’: the sampling interval in seconds at which statistical data should be collected; 5) ‘$statType’: the down-sampling operator to use while performing down-sampling on stats data; 6) ‘$orderby’; 7) ‘$page’; 8) ‘$limit’; and 9) ‘$filter’: the OData filter to use, e.g. ‘stats/hypervisorCpuUsagePpm gt 100000 and stats/guestMemoryUsagePpm lt 2000000.’ | GET |
| ntnx_vmm_py_client | vmm | vmm/v4.0/esxi/stats/vms/:extId | Get VM stats for a given VM. Users can fetch the stats by specifying the following params in the request query: 1) ‘$select’: comma-separated attributes with the prefix ‘stats/’, e.g. ‘stats/checkScore’. 2) ‘$startTime’: the start time for which stats should be reported, e.g. ‘2023-01-01T12:00:00.000-08:00’; 3) ‘$endTime’: the end time for which stats should be reported; 4) ‘$samplingInterval’: the sampling interval in seconds at which statistical data should be collected; 5) ‘$statType’: the down-sampling operator to use while performing down-sampling on stats data | GET |
| ntnx_vmm_py_client | vmm | vmm/v4.0/esxi/stats/vms/:vmExtId/nics/:extId | Fetches the stats for the specified VM NIC. Users can fetch the stats by specifying the following params in the request query: 1) ‘$select’: comma-separated attributes with the prefix ‘stats/’, e.g. ‘stats/checkScore’. 2) ‘$startTime’: the start time for which stats should be reported, e.g. ‘2023-01-01T12:00:00.000-08:00’; 3) ‘$endTime’: the end time for which stats should be reported; 4) ‘$samplingInterval’: the sampling interval in seconds at which statistical data should be collected; 5) ‘$statType’: the down-sampling operator to use while performing down-sampling on stats data | GET |
| ntnx_vmm_py_client | vmm | vmm/v4.0/esxi/stats/vms/:vmExtId/disks/:extId | Fetches the stats for the specified VM disk. Users can fetch the stats by specifying the following params in the request query: 1) ‘$select’: comma-separated attributes with the prefix ‘stats/’, e.g. ‘stats/checkScore’. 2) ‘$startTime’: the start time for which stats should be reported, e.g. ‘2023-01-01T12:00:00.000-08:00’; 3) ‘$endTime’: the end time for which stats should be reported; 4) ‘$samplingInterval’: the sampling interval in seconds at which statistical data should be collected; 5) ‘$statType’: the down-sampling operator to use while performing down-sampling on stats data | GET |
| ntnx_networking_py_client | networking | networking/v4.0/stats/layer2-stretches/:extId | Get Layer2Stretch statistics. | GET |
| ntnx_networking_py_client | networking | networking/v4.0/stats/load-balancer-sessions/:extId | Get load balancer session listener and target statistics | GET |
| ntnx_networking_py_client | networking | networking/v4.0/stats/routing-policies/$actions/clear | Clear the value in packet and byte counters of all Routing Policies in the chosen VPC or a particular routing policy in the chosen VPC. | POST |
| ntnx_networking_py_client | networking | networking/v4.0/stats/traffic-mirrors/:extId | Get Traffic mirror session statistics. | GET |
| ntnx_networking_py_client | networking | networking/v4.0/stats/vpc/:vpcExtId/external-subnets/:extId | Get VPC North-South statistics. | GET |
| ntnx_networking_py_client | networking | networking/v4.0/stats/vpn-connections/:extId | Get VPN connection statistics. | GET |
| ntnx_aiops_py_client | aiops | aiops/v4.0/stats/sources/:sourceExtId/entities/:extId | Returns a list of attributes and metrics (time series data) that are available for a given entity type. | GET |
| ntnx_aiops_py_client | aiops | aiops/v4.0/stats/scenarios/:extId | Get the statistics data of the WhatIf Scenario identified by the provided ExtId. | GET |
| ntnx_clustermgmt_py_client | clustermgmt | clustermgmt/v4.0/stats/clusters/:extId | Get the statistics data of the cluster identified by {clusterExtId}. | GET |
| ntnx_clustermgmt_py_client | clustermgmt | clustermgmt/v4.0/stats/clusters/:clusterExtId/hosts/:extId | Get the statistics data of the host identified by {hostExtId} belonging to the cluster identified by {clusterExtId}. | GET |
| ntnx_clustermgmt_py_client | clustermgmt | clustermgmt/v4.0/stats/disks/:extId | Fetch the stats information of the Disk identified by external identifier. | GET |
| ntnx_clustermgmt_py_client | clustermgmt | clustermgmt/v4.0/stats/storage-containers/:extId | Fetches the statistical information for the Storage Container identified by external identifier.. | GET |
| ntnx_volumes_py_client | volumes | volumes/v4.0/stats/volume-groups/:extId | Query the Volume Group stats identified by {extId}. | GET |
| ntnx_volumes_py_client | volumes | volumes/v4.0/stats/volume-groups/:volumeGroupExtId/disks/:extId | Query the Volume Disk stats identified by {diskExtId}. | GET |
Regardless of which module you have to query for stats, every stats endpoint with a GET method will require the following inputs:
- start time and end time: this is a date and time in ISO-8601 format. What’s that you day? To get the correct format in python, use something like this:
start_time = (datetime.datetime.now(datetime.timezone.utc)).isoformat(). This assumes of course that you have imported the datetime module withimport datetime. - select: this can be
*if you want all available metrics or a list of metrics you want to retrieve (you got the list of available metrics from the aiops module above, remember?) - stat type: this is one of the following:
- “
AVG“: Aggregation indicating mean or average of all values. - “
MIN“: Aggregation containing lowest of all values. - “
MAX“: Aggregation containing highest of all values. - “
LAST“: Aggregation containing only the last recorded value. - “
SUM“: Aggregation with sum of all values. - “
COUNT“: Aggregation containing total count of values.
- “
- sampling interval: this is an integer indicating in seconds the sampling interval (5 for 5 seconds, 30 for 30 seconds, etc…)
Some endpoints will also let you specify an OData filter (such as a vm name). An example of a query filter using an entity uuid would be:
query_filter = "extId eq 'b42889c2-1d60-4fde-b192-37c52263a086'"Now that we have established the ground rules, let’s walk thru a code example.
We’ll start by querying the API to see which metrics are available for each entity type. Most of the concepts we’ll use in this example have been explained in details in parts 1 and 2 covering the basics of how to use the Nutanix v4 API with the Python SDK.
Print statements in the code sample use a Python class to display output in different colors and use different modules to display timestamps as well, so here is the overall modules we need to import for now as well as the code for that Python class:
from concurrent.futures import ThreadPoolExecutor, as_completed
import math
import time
import datetime
import argparse
import getpass
from humanfriendly import format_timespan
import urllib3
import pandas as pd
import keyring
import tqdm
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import ntnx_aiops_py_client
import ntnx_vmm_py_client
class PrintColors:
"""Used for colored output formatting.
"""
OK = '\033[92m' #GREEN
SUCCESS = '\033[96m' #CYAN
DATA = '\033[097m' #WHITE
WARNING = '\033[93m' #YELLOW
FAIL = '\033[91m' #RED
STEP = '\033[95m' #PURPLE
RESET = '\033[0m' #RESET COLORNote that we’ll use all those modules eventually, including plotly to generate dynamic graphs of the metrics we’ll collect. The overall goal of the script will be to generate graphs for a number of specified virtual machines for a specified period of time.
First, we need to find out which sources are available from the API:
import ntnx_aiops_py_client
#* initialize variable for API client configuration
api_client_configuration = ntnx_aiops_py_client.Configuration()
api_client_configuration.host = api_server
api_client_configuration.username = username
api_client_configuration.password = secret
if secure is False:
#! suppress warnings about insecure connections
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
#! suppress ssl certs verification
api_client_configuration.verify_ssl = False
#* getting list of sources
client = ntnx_aiops_py_client.ApiClient(configuration=api_client_configuration)
entity_api = ntnx_aiops_py_client.StatsApi(api_client=client)
print(f"{PrintColors.OK}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [INFO] Fetching available sources...{PrintColors.RESET}")
response = entity_api.get_sources_v4()
source_ext_id = next(iter([source.ext_id for source in response.data if source.source_name == 'nutanix']))Note here that what we are ultimately after if the extId (or uuid) of the nutanix source. We’re also using variables like api_server, username or secret which are assumed to be arguments of the script. The final version of the script will have all of this baked in, so bear with me.
Once we have that information, we’ll want to fetch descriptors from the API which will tell us what metrics are available for each entity type.
We’ll want that process to be multi-threaded in case there are a lot of pages of data to retrieve from the API, so step one will be to come up with a function that we’ll be able to leverage with the concurrent module.
def fetch_entity_descriptors(client,source_ext_id,page,limit=50):
'''fetch_entity_descriptors function.
Args:
client: a v4 Python SDK client object.
source_ext_id: uuid of a valid source.
page: page number to fetch.
limit: number of entities to fetch.
Returns:
'''
entity_api = ntnx_aiops_py_client.StatsApi(api_client=client)
response = entity_api.get_entity_descriptors_v4(sourceExtId=source_ext_id,_page=page,_limit=limit)
return responseWe then proceed to use this function with the concurrent module (combined here with tqdm so that we have a nive progress bar):
#* getting entities and metrics descriptor for nutanix source
print(f"{PrintColors.OK}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [INFO] Fetching entities and descriptors for source nutanix...{PrintColors.RESET}")
entity_list=[]
response = entity_api.get_entity_descriptors_v4(sourceExtId=source_ext_id,_page=0,_limit=1)
total_available_results=response.metadata.total_available_results
page_count = math.ceil(total_available_results/limit)
with tqdm.tqdm(total=page_count, desc="Fetching pages") as progress_bar:
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(
fetch_entity_descriptors,
client=client,
source_ext_id=source_ext_id,
page=page_number,
limit=limit
) for page_number in range(0, page_count, 1)]
for future in as_completed(futures):
try:
entities = future.result()
entity_list.extend(entities.data)
except Exception as e:
print(f"{PrintColors.WARNING}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [WARNING] Task failed: {e}{PrintColors.RESET}")
finally:
progress_bar.update(1)
entity_descriptors_list = entity_listNote how we first retrieve the total number of pages and then loop thru each page to eventually build entity_list which we then assign to entity_descriptors_list.
We now need to display this information:
descriptors={}
for item in entity_descriptors_list:
entity_type = item.entity_type
descriptors[entity_type] = {}
for metric in item.metrics:
metric_name = metric.name
descriptors[entity_type][metric_name] = {}
descriptors[entity_type][metric_name]['name'] = metric.name
descriptors[entity_type][metric_name]['value_type'] = metric.value_type
if metric.additional_properties is not None:
descriptors[entity_type][metric_name]['description'] = next(iter([metric_property.value for metric_property in metric.additional_properties if metric_property.name == 'description']),None)
else:
descriptors[entity_type][metric_name]['description'] = None
for entity_type in descriptors.keys():
print(f"{PrintColors.OK}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [INFO] Available metrics for {entity_type} are:{PrintColors.RESET}")
for metric in sorted(descriptors[entity_type]):
print(f" {descriptors[entity_type][metric]['name']},{descriptors[entity_type][metric]['value_type']},{descriptors[entity_type][metric]['description']}")Note how for each entity type, we display the internal metric name, its data type, as well as the description if there is one available.
Using this code, we can get a list similar to this (here for entity type vm):
checkScore,INT,None
cluster,STRING,None
controllerAvgIoLatencyMicros,INT,I/O latency in milliseconds from the Storage Controller.
controllerAvgReadIoLatencyMicros,INT,Storage Controller read latency in milliseconds.
controllerAvgReadIoSizeKb,INT,None
controllerAvgWriteIoLatencyMicros,INT,Storage Controller write latency in milliseconds.
controllerAvgWriteIoSizeKb,INT,None
controllerIoBandwidthKbps,INT,Data transferred in KB/second from the Storage Controller.
controllerNumIo,INT,None
controllerNumIops,INT,Input/Output operations per second from the Storage Controller.
controllerNumRandomIo,INT,None
controllerNumReadIo,INT,None
controllerNumReadIops,INT,Input/Output read operations per second from the Storage Controller
controllerNumSeqIo,INT,None
controllerNumWriteIo,INT,None
controllerNumWriteIops,INT,Input/Output write operations per second from the Storage Controller
controllerOplogDrainDestHddBytes,INT,None
controllerOplogDrainDestSsdBytes,INT,None
controllerRandomIoPpm,INT,None
controllerReadIoBandwidthKbps,INT,Read data transferred in KB/second from the Storage Controller.
controllerReadIoPpm,INT,Percent of Storage Controller IOPS that are reads.
controllerReadSourceEstoreHddLocalBytes,INT,None
controllerReadSourceEstoreHddRemoteBytes,INT,None
controllerReadSourceEstoreSsdLocalBytes,INT,None
controllerReadSourceEstoreSsdRemoteBytes,INT,None
controllerReadSourceOplogBytes,INT,None
controllerSeqIoPpm,INT,None
controllerSharedUsageBytes,INT,Shared Data usage
controllerSnapshotUsageBytes,INT,Snapshot usage Bytes
controllerStorageTierSsdUsageBytes,INT,None
controllerTimespanMicros,INT,None
controllerTotalIoSizeKb,INT,None
controllerTotalIoTimeMicros,INT,None
controllerTotalReadIoSizeKb,INT,None
controllerTotalReadIoTimeMicros,INT,None
controllerTotalTransformedUsageBytes,INT,None
controllerUserBytes,INT,Disk Usage Bytes
controllerWriteDestEstoreHddBytes,INT,None
controllerWriteDestEstoreSsdBytes,INT,None
controllerWriteIoBandwidthKbps,INT,Write data transferred in KB/second from the Storage Controller.
controllerWriteIoPpm,INT,Percent of Storage Controller IOPS that are writes.
controllerWss120SecondReadMb,INT,None
controllerWss120SecondUnionMb,INT,None
controllerWss120SecondWriteMb,INT,None
controllerWss3600SecondReadMb,INT,Read I/O working set size
controllerWss3600SecondUnionMb,INT,I/O working set size
controllerWss3600SecondWriteMb,INT,Write I/O working set size
diskCapacityBytes,INT,None
diskUsagePpm,INT,Disk Usage in percentage
frameBufferUsagePpm,INT,Usage of the GPU's framebuffer
gpuUsagePpm,INT,Usage of the GPU
guestMemoryUsagePpm,INT,None
hypervisorAvgIoLatencyMicros,INT,None
hypervisorCpuReadyTimePpm,INT,Hypervisor CPU ready time
hypervisorCpuUsagePpm,INT,Percent of CPU used by the hypervisor.
hypervisorIoBandwidthKbps,INT,None
hypervisorMemoryBalloonReclaimTargetBytes,INT,Memory Swap Out Rate
hypervisorMemoryBalloonReclaimedBytes,INT,Memory Balloon Bytes
hypervisorMemoryUsagePpm,INT,Hypervisor Memory Usage percentage
hypervisorNumIo,INT,None
hypervisorNumIops,INT,None
hypervisorNumReadIo,INT,None
hypervisorNumReadIops,INT,None
hypervisorNumReceivePacketsDropped,INT,Network Receive Packets Dropped
hypervisorNumReceivedBytes,INT,Write data transferred in KB/second from the Storage Controller.
hypervisorNumTransmitPacketsDropped,INT,Network Transmit Packets Dropped
hypervisorNumTransmittedBytes,INT,Write data transferred per second in KB/second.
hypervisorNumWriteIo,INT,None
hypervisorNumWriteIops,INT,None
hypervisorReadIoBandwidthKbps,INT,None
hypervisorSwapInRateKbps,INT,Memory Swap In Rate
hypervisorSwapOutRateKbps,INT,Memory Swap Out Rate
hypervisorTimespanMicros,INT,None
hypervisorTotalIoSizeKb,INT,None
hypervisorTotalIoTimeMicros,INT,None
hypervisorTotalReadIoSizeKb,INT,None
hypervisorType,STRING,None
hypervisorVmRunningTimeUsecs,INT,None
hypervisorWriteIoBandwidthKbps,INT,None
memoryReservedBytes,INT,None
memoryUsageBytes,INT,None
memoryUsagePpm,INT,Percent of memory used by the VM.
numVcpusUsedPpm,INT,NoneNow that we know which metrics are available, we can focus on actually retrieving these metrics for one or more vm entities and do something with them (such as build graphs).
As usual, we’ll need to initialize an API client for the vmm module:
#* initialize variable for API client configuration
api_client_configuration = ntnx_vmm_py_client.Configuration()
api_client_configuration.host = api_server
api_client_configuration.username = username
api_client_configuration.password = secret
if secure is False:
#! suppress warnings about insecure connections
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
#! suppress ssl certs verification
api_client_configuration.verify_ssl = False
client = ntnx_vmm_py_client.ApiClient(configuration=api_client_configuration)Now that we have our client, we can get our vm entity from the API:
#* fetch vm object to figure out extId
entity_api = ntnx_vmm_py_client.VmApi(api_client=client)
query_filter = f"name eq '{vm}'"
response = entity_api.list_vms(_filter=query_filter)
vm_uuid = response.data[0].ext_idNote how we use a filter here to grab only the vm we’re interested in. What we’re really after is its extId/uuid, which we can then use to grab metrics:
#* fetch metrics for vm
entity_api = ntnx_vmm_py_client.StatsApi(api_client=client)
start_time = (datetime.datetime.now(datetime.timezone.utc)-datetime.timedelta(minutes=minutes_ago)).isoformat()
end_time = (datetime.datetime.now(datetime.timezone.utc)).isoformat()
response = entity_api.get_vm_stats_by_id(vm_uuid, _startTime=start_time, _endTime=end_time, _samplingInterval=sampling_interval, _statType=stat_type, _select='*')
vm_stats = [stat for stat in response.data.stats if stat.cluster is None]we’re figuring out start and end time here using a number of minutes we want to look back at (the minutes_ago variable) and we’re grabbing all available metrics for that time period with _select='*'.
We’re then removing any results that match cluster information with the statement on line 6 since that contains the cluster uuid and would prevent us from creating graphs later.
Next, we’ll build pandas dataframe from that data so that we can easily create graphs with plotly later:
#* building pandas dataframe from the retrieved data
data_points = []
for data_point in vm_stats:
data_points.append(data_point.to_dict())
df = pd.DataFrame(data_points)
df = df.set_index('timestamp')
df.drop('_reserved', axis=1, inplace=True)
df.drop('_object_type', axis=1, inplace=True)
df.drop('_unknown_fields', axis=1, inplace=True)
df.drop('cluster', axis=1, inplace=True)
df.drop('hypervisor_type', axis=1, inplace=True)Note that we’re converting the retrieved data to Python dict with the .to_dict() function and that we are dropping a number of columns we won’t use in our graph anyway.
Now we’re building graphs (multiple on one page) with plotly with that dataframe:
#* building graphs
df = df.dropna(subset=['disk_usage_ppm'])
df['disk_usage'] = (df['disk_usage_ppm'] / 10000).round(2)
df = df.dropna(subset=['memory_usage_ppm'])
df['memory_usage'] = (df['memory_usage_ppm'] / 10000).round(2)
df = df.dropna(subset=['hypervisor_cpu_usage_ppm'])
df['hypervisor_cpu_usage'] = (df['hypervisor_cpu_usage_ppm'] / 10000).round(2)
df = df.dropna(subset=['hypervisor_cpu_ready_time_ppm'])
df['hypervisor_cpu_ready_time'] = (df['hypervisor_cpu_ready_time_ppm'] / 10000).round(2)
fig = make_subplots(rows=2, cols=2,
subplot_titles=(f"{vm} Overview", f"{vm} Storage IOPS", f"{vm} Storage Bandwidth", f"{vm} Storage Latency"),
x_title="Time") # Shared x-axis title
# Subplot 1: Overview
y_cols1 = ["hypervisor_cpu_usage", "hypervisor_cpu_ready_time", "memory_usage", "disk_usage"]
for y_col in y_cols1:
fig.add_trace(go.Scatter(x=df.index, y=df[y_col], hovertemplate="%{x}<br>%%{y}", name=y_col, mode='lines', legendgroup='group1'), row=1, col=1)
fig.update_yaxes(title_text="% Utilized", range=[0, 100], row=1, col=1)
# Subplot 2: Storage IOPS
y_cols2 = ["controller_num_iops", "controller_num_read_iops", "controller_num_write_iops"]
for y_col in y_cols2:
fig.add_trace(go.Scatter(x=df.index, y=df[y_col], hovertemplate="%{x}<br>%{y} iops", name=y_col, mode='lines', legendgroup='group2'), row=1, col=2)
fig.update_yaxes(title_text="IOPS", row=1, col=2)
# Subplot 3: Storage Bandwidth
y_cols3 = ["controller_io_bandwidth_kbps", "controller_read_io_bandwidth_kbps", "controller_write_io_bandwidth_kbps"]
for y_col in y_cols3:
fig.add_trace(go.Scatter(x=df.index, y=df[y_col], hovertemplate="%{x}<br>%{y} kbps", name=y_col, mode='lines', legendgroup='group3'), row=2, col=1)
fig.update_yaxes(title_text="Kbps", row=2, col=1)
# Subplot 4: Storage Latency
y_cols4 = ["controller_avg_io_latency_micros", "controller_avg_read_io_latency_micros", "controller_avg_write_io_latency_micros"]
for y_col in y_cols4:
fig.add_trace(go.Scatter(x=df.index, y=df[y_col], hovertemplate="%{x}<br>%{y} usec", name=y_col, mode='lines', legendgroup='group4'), row=2, col=2)
fig.update_yaxes(title_text="Microseconds", row=2, col=2)
fig.update_layout(height=800, legend_title_text="Metric") # Shared legend title
fig.show()First we’re manipulating data a bit from lines 2 to 9 by removing null values and performing math calculation on the ppm metrics so that we can display percentages.
We’re then creating subplots (different graphs on the same page) from lines 11 to 34 using plotly.
Finally, we’re opening that page with line 35 (which we’ll open your default browser and display the graphs).
What if we wanted to do this for multiple vms you ask? We would pull all of this in a function:
def get_vm_metrics(client,vm,minutes_ago,sampling_interval,stat_type):
'''get_vm_metrics function.
Fetches metrics for a specified vm and generates graphs for that entity.
Args:
client: a v4 Python SDK client object.
vm: a virtual machine name
minutes_ago: integer indicating the number of minutes to get metrics for (exp: 60 would mean get the metrics for the last hour).
sampling_interval: integer used to specify in seconds the sampling interval.
stat_type: The operator to use while performing down-sampling on stats data. Allowed values are SUM, MIN, MAX, AVG, COUNT and LAST.
Returns:
'''
#* fetch vm object to figure out extId
entity_api = ntnx_vmm_py_client.VmApi(api_client=client)
query_filter = f"name eq '{vm}'"
response = entity_api.list_vms(_filter=query_filter)
vm_uuid = response.data[0].ext_id
#* fetch metrics for vm
entity_api = ntnx_vmm_py_client.StatsApi(api_client=client)
start_time = (datetime.datetime.now(datetime.timezone.utc)-datetime.timedelta(minutes=minutes_ago)).isoformat()
end_time = (datetime.datetime.now(datetime.timezone.utc)).isoformat()
response = entity_api.get_vm_stats_by_id(vm_uuid, _startTime=start_time, _endTime=end_time, _samplingInterval=sampling_interval, _statType=stat_type, _select='*')
vm_stats = [stat for stat in response.data.stats if stat.cluster is None]
#* building pandas dataframe from the retrieved data
data_points = []
for data_point in vm_stats:
data_points.append(data_point.to_dict())
df = pd.DataFrame(data_points)
df = df.set_index('timestamp')
df.drop('_reserved', axis=1, inplace=True)
df.drop('_object_type', axis=1, inplace=True)
df.drop('_unknown_fields', axis=1, inplace=True)
df.drop('cluster', axis=1, inplace=True)
df.drop('hypervisor_type', axis=1, inplace=True)
#* building graphs
df = df.dropna(subset=['disk_usage_ppm'])
df['disk_usage'] = (df['disk_usage_ppm'] / 10000).round(2)
df = df.dropna(subset=['memory_usage_ppm'])
df['memory_usage'] = (df['memory_usage_ppm'] / 10000).round(2)
df = df.dropna(subset=['hypervisor_cpu_usage_ppm'])
df['hypervisor_cpu_usage'] = (df['hypervisor_cpu_usage_ppm'] / 10000).round(2)
df = df.dropna(subset=['hypervisor_cpu_ready_time_ppm'])
df['hypervisor_cpu_ready_time'] = (df['hypervisor_cpu_ready_time_ppm'] / 10000).round(2)
fig = make_subplots(rows=2, cols=2,
subplot_titles=(f"{vm} Overview", f"{vm} Storage IOPS", f"{vm} Storage Bandwidth", f"{vm} Storage Latency"),
x_title="Time") # Shared x-axis title
# Subplot 1: Overview
y_cols1 = ["hypervisor_cpu_usage", "hypervisor_cpu_ready_time", "memory_usage", "disk_usage"]
for y_col in y_cols1:
fig.add_trace(go.Scatter(x=df.index, y=df[y_col], hovertemplate="%{x}<br>%%{y}", name=y_col, mode='lines', legendgroup='group1'), row=1, col=1)
fig.update_yaxes(title_text="% Utilized", range=[0, 100], row=1, col=1)
# Subplot 2: Storage IOPS
y_cols2 = ["controller_num_iops", "controller_num_read_iops", "controller_num_write_iops"]
for y_col in y_cols2:
fig.add_trace(go.Scatter(x=df.index, y=df[y_col], hovertemplate="%{x}<br>%{y} iops", name=y_col, mode='lines', legendgroup='group2'), row=1, col=2)
fig.update_yaxes(title_text="IOPS", row=1, col=2)
# Subplot 3: Storage Bandwidth
y_cols3 = ["controller_io_bandwidth_kbps", "controller_read_io_bandwidth_kbps", "controller_write_io_bandwidth_kbps"]
for y_col in y_cols3:
fig.add_trace(go.Scatter(x=df.index, y=df[y_col], hovertemplate="%{x}<br>%{y} kbps", name=y_col, mode='lines', legendgroup='group3'), row=2, col=1)
fig.update_yaxes(title_text="Kbps", row=2, col=1)
# Subplot 4: Storage Latency
y_cols4 = ["controller_avg_io_latency_micros", "controller_avg_read_io_latency_micros", "controller_avg_write_io_latency_micros"]
for y_col in y_cols4:
fig.add_trace(go.Scatter(x=df.index, y=df[y_col], hovertemplate="%{x}<br>%{y} usec", name=y_col, mode='lines', legendgroup='group4'), row=2, col=2)
fig.update_yaxes(title_text="Microseconds", row=2, col=2)
fig.update_layout(height=800, legend_title_text="Metric") # Shared legend title
fig.show()…and then we would use concurrent to multi-thread the processing like so:
#* initialize variable for API client configuration
api_client_configuration = ntnx_vmm_py_client.Configuration()
api_client_configuration.host = api_server
api_client_configuration.username = username
api_client_configuration.password = secret
if secure is False:
#! suppress warnings about insecure connections
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
#! suppress ssl certs verification
api_client_configuration.verify_ssl = False
client = ntnx_vmm_py_client.ApiClient(configuration=api_client_configuration)
with tqdm.tqdm(total=len(vms), desc="Processing VMs") as progress_bar:
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(
get_vm_metrics,
client=client,
vm=vm,
minutes_ago=minutes_ago,
sampling_interval=sampling_interval,
stat_type=stat_type
) for vm in vms]
for future in as_completed(futures):
try:
entities = future.result()
except Exception as e:
print(f"{PrintColors.WARNING}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [WARNING] Task failed: {e}{PrintColors.RESET}")
finally:
progress_bar.update(1)In addition to creating graphs, it may be interesting to export the metrics data to csv, so we’ll add the following code to the get_vm_metrics function:
for column in df.columns:
df[column].to_csv(f"{vm}_{column}.csv", index=True)That will create a csv file for each metric for each vm being processed.
Time to pull it all together with arguments, including credentials:
if __name__ == '__main__':
# * parsing script arguments
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("-p", "--prism", help="prism server.")
parser.add_argument("-u", "--username", default='admin', help="username for prism server.")
parser.add_argument("-s", "--secure", default=False, action=argparse.BooleanOptionalAction, help="Control SSL certs verification.")
parser.add_argument("-sh", "--show", action=argparse.BooleanOptionalAction, help="Show available entity types and metrics.")
parser.add_argument("-g", "--graph", action=argparse.BooleanOptionalAction, help="Indicate you want graphs to be generated. Defaults to True.")
parser.add_argument("-e", "--export", action=argparse.BooleanOptionalAction, help="Indicate you want csv exports to be generated (1 csv file per metric for each vm). Defaults to False.")
parser.add_argument("-v", "--vm", type=str, help="Comma separated list of VM names you want to process.")
parser.add_argument("-c", "--csv", type=str, help="Path and name of csv file with vm names (header: vm_name and then one vm name per line).")
parser.add_argument("-t", "--time", type=int, default=5, help="Integer used to specify how many minutes ago you want to collect metrics for (defaults to 5 minutes ago).")
parser.add_argument("-i", "--interval", type=int, default=30, help="Integer used to specify in seconds the sampling interval (defaults to 30 seconds).")
parser.add_argument("-st", "--stat_type", default="AVG", choices=["AVG","MIN","MAX","LAST","SUM","COUNT"], help="The operator to use while performing down-sampling on stats data. Allowed values are SUM, MIN, MAX, AVG, COUNT and LAST. Defaults to AVG")
args = parser.parse_args()
# * check for password (we use keyring python module to access the workstation operating system password store in an "ntnx" section)
print(f"{PrintColors.OK}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [INFO] Trying to retrieve secret for user {args.username} from the password store.{PrintColors.RESET}")
pwd = keyring.get_password("ntnx",args.username)
if not pwd:
try:
pwd = getpass.getpass()
keyring.set_password("ntnx",args.username,pwd)
except Exception as error:
print(f"{PrintColors.FAIL}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [ERROR] {error}.{PrintColors.RESET}")
exit(1)
if args.show is True:
target_vms = None
elif args.csv:
data=pd.read_csv(args.csv)
target_vms = data['vm_name'].tolist()
elif args.vm:
target_vms = args.vm.split(',')
main(api_server=args.prism,username=args.username,secret=pwd,secure=args.secure,show=args.show,vms=target_vms,minutes_ago=args.time,sampling_interval=args.interval,stat_type=args.stat_type,graph=args.graph,csv_export=args.export)Note that we can now control if graphs and/or csv exports are produced.
The rest of the code has to be modified as well to now work with all those arguments. The final result is available here.
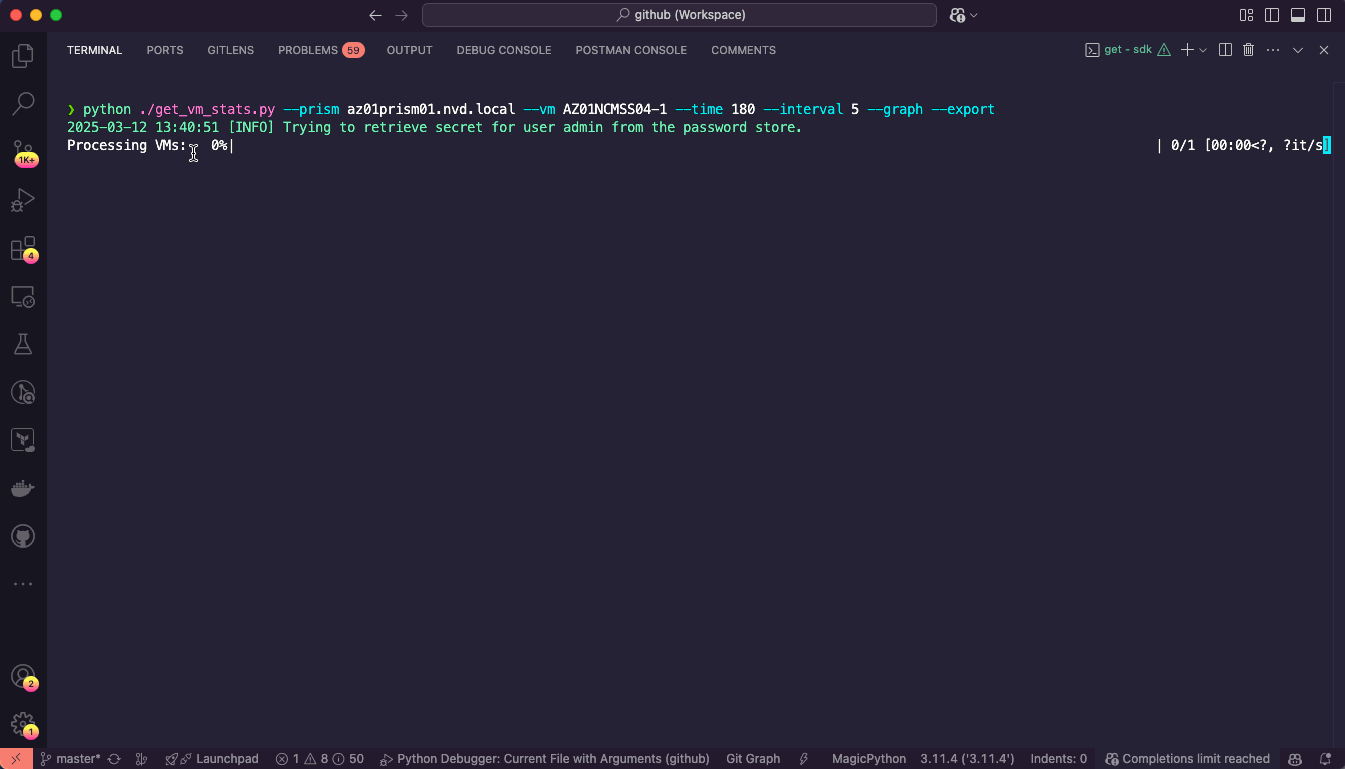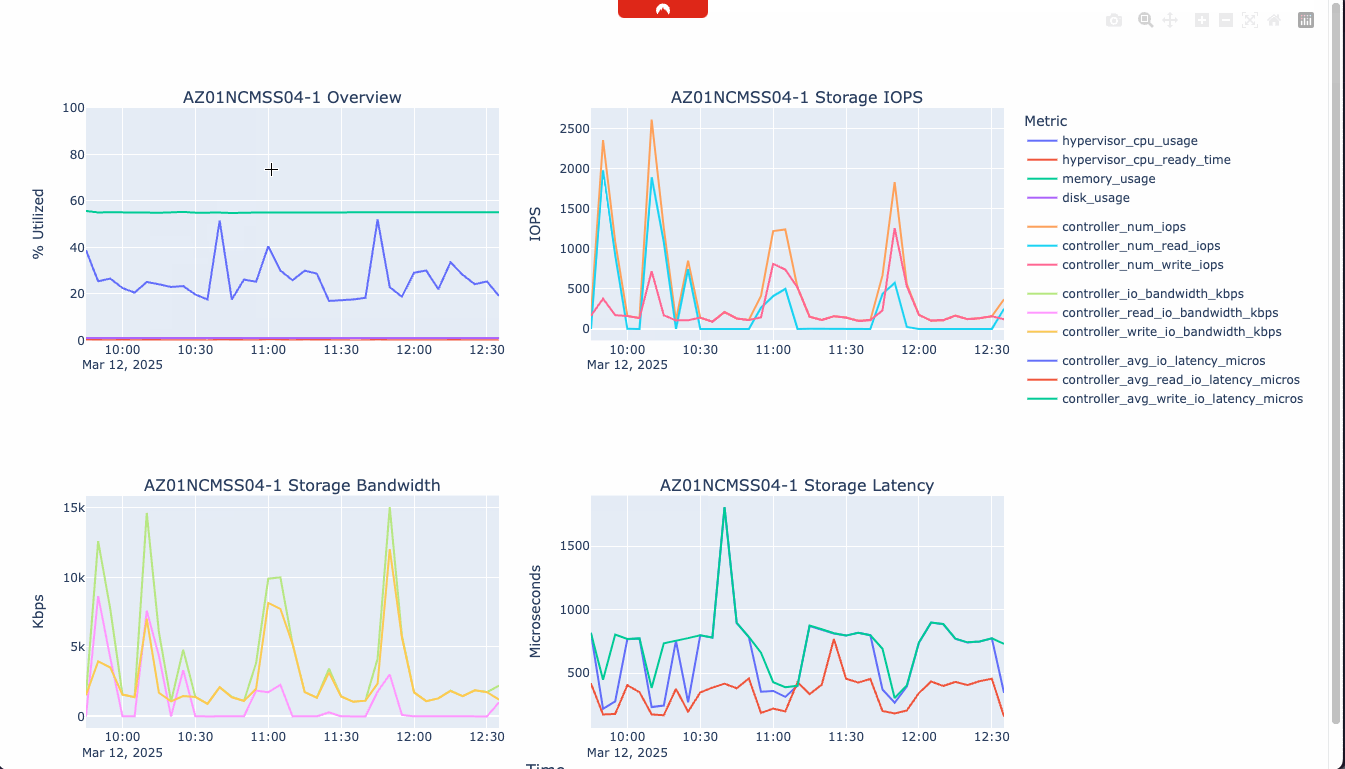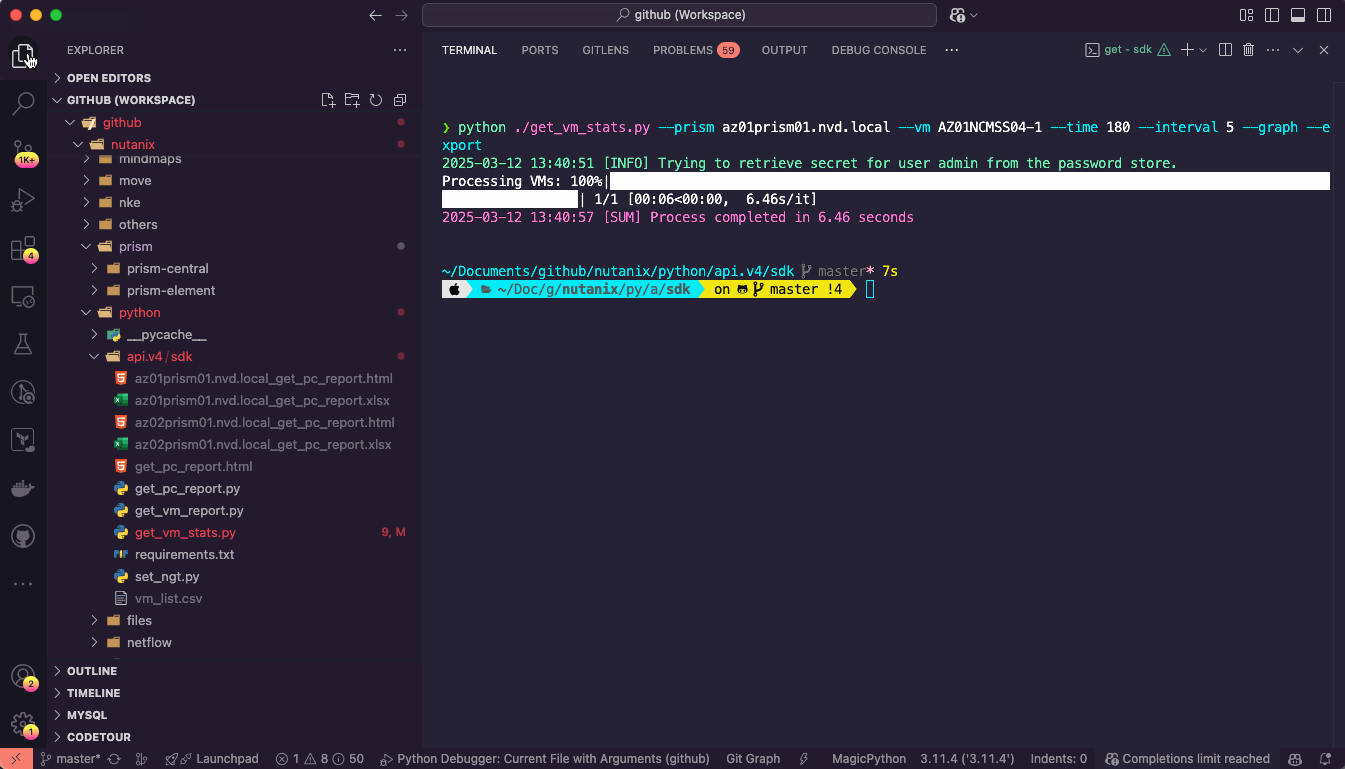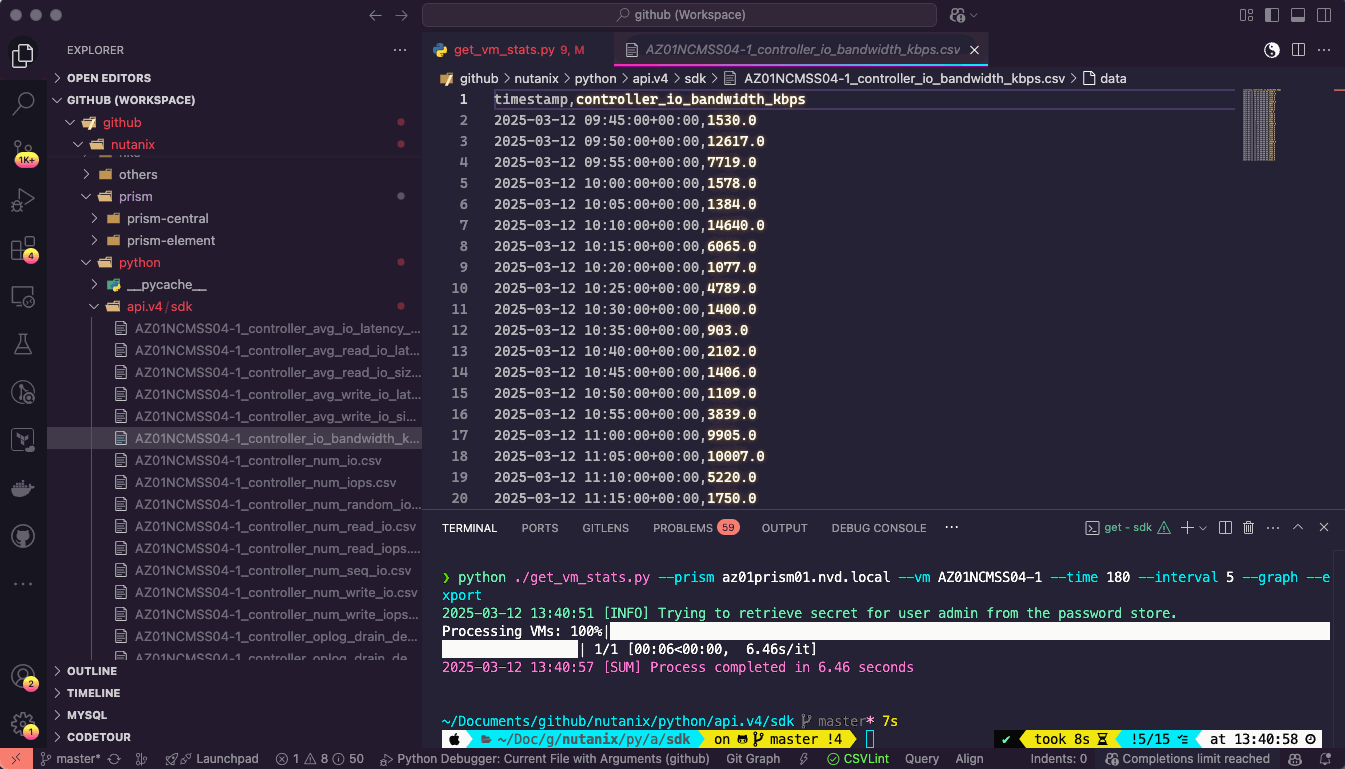
Let’s now have a look at the script executing and the result:
In a future post, I’ll show how to apply all this knowledge to build a custom prometheus node exporter for Nutanix resources.