In part 1 of this series, we covered the basics of using the Nutanix API v4 API Python SDK including:
- How to decide which module you will require
- How to initialize the API client and use functions on objects
- How to use pagination with multithreading for maximum efficiency
In part 2, we will cover:
- How to start building a reporting script that you will be able to pass arguments to
- How to deal securely with credentials in this script using built-in operating systems credentials vaults
- How to turn API entities data into dynamic HTML reports and Excel spreadsheets
To illustrate this, we’ll walk you thru building a new script using all those concepts from scratch.
If all you’re interested in is the script, not the knowledge that goes along with it, then so be it. The script is available here.
Building a Python script template that you can pass arguments to
While I don’t pretend to be a Python developer, I’ve now scripted APIs using Python for a number of years and I pretty much always use the same code structure:
- Python scripts should start with a docstring that documents what they do and how to use them.
- They should then contain import statements that list modules and functions within modules that the script will require.
- You then declare classes that the script will use if any. I usually have one for doing pretty colored outputs to stdout.
- You then declare functions that the script uses and which aren’t available in any of the modules you already imported. This includes the main function of the script.
- Finally, you have code so that the script itself can be used both as a standalone script or a module. In this section, I usually also deal with arguments and how I pass them to the main function.
Docstring
This is what our script docstring will look like:
""" gets misc entities list from Prism Central using v4 API and python SDK
Args:
prism: The IP or FQDN of Prism.
username: The Prism user name.
secure: True or False to control SSL certs verification.
Returns:
html and excel report files.
"""Nothing fancy. We document what the script can be used for, what input it requires, and what output it produces.
Import
This is what our import section will look like:
#region #*IMPORT
from concurrent.futures import ThreadPoolExecutor, as_completed
import math
import time
import datetime
import argparse
import getpass
from humanfriendly import format_timespan
import urllib3
import pandas as pd
import datapane
import keyring
import tqdm
import ntnx_vmm_py_client
import ntnx_clustermgmt_py_client
import ntnx_networking_py_client
import ntnx_prism_py_client
import ntnx_iam_py_client
#endregion #*IMPORTNote that I use #region and #enregion tags to enable easy opening and collapsing of sections in the script when using an IDE like Visual Studio Code (which is what I use). I also use the Better Comments extension in vscode with the #* tags to highlight in green the region name which makes it even easier to navigate code within longer scripts.
At the top of the import region, I put built-in (not requiring any specific installation) Python modules from which I import only specific functions. I then have a block of all the built-in Python modules that I import whole. I then list installed modules from which I import only specific functions, installed modules that I import whole, and finally, the last block lists the Nutanix v4 API SDK modules I import.
Here is a detailed explanation of the full list. We’ll use:
- concurrent.futures for multi-threaded processing (when we want to retrieve multiple pages of entities from the API at once)
- math, time and datetime to manipulate numbers and date/time formats for output
- argparse to deal with passing arguments to the script
- getpass to capture and encode credentials
- humanfriendly to make sense of API objects timestamps in a human readable format (nobody, besides the Terminator, knows how many microseconds elapsed since January 1st 1970)
- urllib3 to disable warnings that pollute our stdout output when unsecure calls are made to the API (not everybody cares to replace SSL certs, even though they should)
- pandas to easily structure API entities data into objects that can be exported to various formats (like html or excel)
- datapane to produce the final dynamic (and pretty sexy looking) html report with built-in capabilities such as multi-pages, SQL queries and csv export.
- keyring to store securely credentials inside guest operating systems built-in vaults (such as keychain on Mac OSX) because nobody likes to type their 20 character password every time they run a script; unless you’re preparing for the keyboard typing olympic games)
- tqdm to display progress bars (staring at a blinking cursor wondering what is happening ain’t no fun)
- ntnx_vmm_py_client to retrieve information about virtual machines from the Nutanix API
- ntnx_clustermgmt_py_client to retrieve information about clusters from the Nutanix API
- ntnx_networking_py_client to retrieve information about subnets from the Nutanix API
- ntnx_prism_py_client to retrieve information about categories from the Nutanix API
- ntnx_iam_py_client to retrieve information about users from the Nutanix API
Now you know. Let’s move on.
Classes
We’ll only use a single custom class whose unique purpose will be to color output to stdout (because the world is grey enough as it is):
#region #*CLASS
class PrintColors:
"""Used for colored output formatting.
"""
OK = '\033[92m' #GREEN
SUCCESS = '\033[96m' #CYAN
DATA = '\033[097m' #WHITE
WARNING = '\033[93m' #YELLOW
FAIL = '\033[91m' #RED
STEP = '\033[95m' #PURPLE
RESET = '\033[0m' #RESET COLOR
#endregion #*CLASSFunctions
Our script will have two functions:
fetch_entitieswhich we’ll use to get entities from the Nutanix API. This function will be generic, meaning that we’ll be able to use it regardless of the module, entity type and list function we need.mainwhich will be baking apple pies (just kidding; what do you honestly thinkmainis used for?)
This is what our fetch_entities function looks like:
#region #*FUNCTIONS
def fetch_entities(client,module,entity_api,function,page,limit=50):
'''fetch_entities function.
Args:
client: a v4 Python SDK client object.
module: name of the v4 Python SDK module to use.
entity_api: name of the entity API to use.
function: name of the function to use.
page: page number to fetch.
limit: number of entities to fetch.
Returns:
'''
entity_api_module = getattr(module, entity_api)
entity_api = entity_api_module(api_client=client)
list_function = getattr(entity_api, function)
response = list_function(_page=page,_limit=limit)
return response
#more on main later
#endregion #*FUNCTIONSNote that our function has a docstring (let’s not be lazy). We use getattr to make it dynamic based on what parameters it is passed. This prevents us from having a specific fetch entities function per API module and entity type. Schwing!
We’ll cover the main function later since that is the bulk of the script. Just be patient. I know, it’s hard.
The unnamed section
This is what the unnamed (whose name shall not be pronounced) looks like:
if __name__ == '__main__':
# * parsing script arguments
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("-p", "--prism", help="prism server.")
parser.add_argument("-u", "--username", default='admin', help="username for prism server.")
parser.add_argument("-s", "--secure", default=False, help="True of False to control SSL certs verification.")
args = parser.parse_args()
# * check for password (we use keyring python module to access the workstation operating system password store in an "ntnx" section)
print(f"{PrintColors.OK}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [INFO] Trying to retrieve secret for user {args.username} from the password store.{PrintColors.RESET}")
pwd = keyring.get_password("ntnx",args.username)
if not pwd:
try:
pwd = getpass.getpass()
keyring.set_password("ntnx",args.username,pwd)
except Exception as error:
print(f"{PrintColors.FAIL}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [ERROR] {error}.{PrintColors.RESET}")
exit(1)
main(api_server=args.prism,username=args.username,secret=pwd,secure=args.secure)This enables you to use the script as is or as a module (not that you would particularly want to).
In here we deal with script arguments in the “parsing script arguments” section, with credentials in the “check for password” section and then we call the main function in the main section. Let’s go over each section.
arguments
This section starts by creating an argument parser object called parser:
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)We then add arguments to that object:
parser.add_argument("-p", "--prism", help="prism server.")
parser.add_argument("-u", "--username", default='admin', help="username for prism server.")
parser.add_argument("-s", "--secure", default=False, help="True of False to control SSL certs verification.")Note that with each argument we add, we specify a short tag (exp: -p for prism), a long tag (exp: --prism) and a help message. We could also specify a type, default value (which makes the argument optional) a list of valid choices… Note that username for example will default to admin if nothing is specified and that secure defaults to False. We’re otherwise just keeping it minimal here. If you are interested in all those options, knock yourself out by reading the argparse doc.
Finally, we ask the argparse module to do its job and parse the script command line to extract those arguments and store everything in a variable called args (and no, it’s not agonizing):
args = parser.parse_args()This makes parsed arguments directly available such as args.prism or args.secure. Schwing!
credentials
This section starts by trying to retrieve the username’s secret from the operating system built-in password vault, in a section called ntnx and store it in a variable called pwd:
pwd = keyring.get_password("ntnx",args.username)What happens if that password does not exist? Thanks for asking:
if not pwd:
try:
pwd = getpass.getpass()
keyring.set_password("ntnx",args.username,pwd)
except Exception as error:
print(f"{PrintColors.FAIL}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [ERROR] {error}.{PrintColors.RESET}")
exit(1)If the password could not be retrieved (as would happen the first time you run the script), we prompt the user for it using getpass with:
pwd = getpass.getpass()We then store that secret into the vault for future uses using keyring:
keyring.set_password("ntnx",args.username,pwd)The rest is boring and dealing with errors.
So, if you’re sharp, you’re thinking: “Wait a minute, what if I ran this script a month ago and since my user password has changed? Then what?“
Good thinking Batman. You would have to delete your secret from the vault using (from your OS command line):
keyring del ntnx <username>You may also be thinking: “Is this really a secure way to deal with credentials?“
I’ll let you read the keyring documentation on that topic. All I can say is that retrieving those secrets is tied to the OS user and only works for that user on that machine. In my book, that sure beats storing secrets in clear text in configuration files, script code or environment variables. Thank you very much.
The main course
Our main function, where all the magic happens, starts just like any other function: with a docstring:
def main(api_server,username,secret,secure=False):
'''main function.
Args:
api_server: IP or FQDN of the REST API server.
username: Username to use for authentication.
secret: Secret for the username.
secure: indicates if certs should be verified.
Returns:
html and excel report files.
'''
start_time = time.time()
limit=100Note that we define the parameters that are passed to this main function, which match the way we call it in the unnamed section of our script.
We also capture the function start time (so that we can report at then end how long processing took), and define a limit of 100 which we’ll use when calling the fetch_entities function later so that we retrieve 100 objects at a time instead of the API default of 50.
The rest of the main function will be organized in regions. We’ll have:
- one region per entity type we need to retrieve and include in our report,
- one region for producing the html output
- one region for producing the excel output
getting and processing entities
Let’s look at an entity region:
#region #?clusters
#* initialize variable for API client configuration
api_client_configuration = ntnx_clustermgmt_py_client.Configuration()
api_client_configuration.host = api_server
api_client_configuration.username = username
api_client_configuration.password = secret
if secure is False:
#! suppress warnings about insecure connections
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
#! suppress ssl certs verification
api_client_configuration.verify_ssl = False
#* getting list of clusters
client = ntnx_clustermgmt_py_client.ApiClient(configuration=api_client_configuration)
entity_api = ntnx_clustermgmt_py_client.ClustersApi(api_client=client)
print(f"{PrintColors.OK}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [INFO] Fetching Clusters...{PrintColors.RESET}")
entity_list=[]
response = entity_api.list_clusters(_page=0,_limit=1)
total_available_results=response.metadata.total_available_results
page_count = math.ceil(total_available_results/limit)
with tqdm.tqdm(total=page_count, desc="Fetching entity pages") as progress_bar:
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(
fetch_entities,
module=ntnx_clustermgmt_py_client,
entity_api='ClustersApi',
client=client,
function='list_clusters',
page=page_number,
limit=limit
) for page_number in range(0, page_count, 1)]
for future in as_completed(futures):
try:
entities = future.result()
entity_list.extend(entities.data)
except Exception as e:
print(f"{PrintColors.WARNING}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [WARNING] Task failed: {e}{PrintColors.RESET}")
finally:
progress_bar.update(1)
cluster_list = entity_list
#* format output
print(f"{PrintColors.OK}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [INFO] Processing {len(entity_list)} entities...{PrintColors.RESET}")
cluster_list_output = []
for entity in cluster_list:
if 'PRISM_CENTRAL' in entity.config.cluster_function:
continue
entity_output = {
'name': entity.name,
'ext_id': entity.ext_id,
'incarnation_id': entity.config.incarnation_id,
'is_available': entity.config.is_available,
'operation_mode': entity.config.operation_mode,
'redundancy_factor': entity.config.redundancy_factor,
'domain_awareness_level': entity.config.fault_tolerance_state.domain_awareness_level,
'current_max_fault_tolerance': entity.config.fault_tolerance_state.current_max_fault_tolerance,
'desired_max_fault_tolerance': entity.config.fault_tolerance_state.desired_max_fault_tolerance,
'upgrade_status': entity.upgrade_status,
'vm_count': entity.vm_count,
'inefficient_vm_count': entity.inefficient_vm_count,
'cluster_arch': entity.config.cluster_arch,
'cluster_function': entity.config.cluster_function,
'hypervisor_types': entity.config.hypervisor_types,
'is_password_remote_login_enabled': entity.config.is_password_remote_login_enabled,
'is_remote_support_enabled': entity.config.is_remote_support_enabled,
'pulse_enabled': entity.config.pulse_status.is_enabled,
'timezone': entity.config.timezone,
'ncc_version': next(iter({ software.version for software in entity.config.cluster_software_map if software.software_type == "NCC" })),
'aos_full_version': entity.config.build_info.full_version,
'aos_commit_id': entity.config.build_info.short_commit_id,
'aos_version': entity.config.build_info.version,
'is_segmentation_enabled': entity.network.backplane.is_segmentation_enabled,
'external_address_ipv4': entity.network.external_address.ipv4.value,
'external_data_service_ipv4': entity.network.external_data_service_ip.ipv4.value,
'external_subnet': entity.network.external_subnet,
'name_server_ipv4_list': list({ name_server.ipv4.value for name_server in entity.network.name_server_ip_list}),
'ntp_server_list': "",
'number_of_nodes': entity.nodes.number_of_nodes,
}
if "fqdn" in entity.network.ntp_server_ip_list:
entity_output['ntp_server_list'] = list({ ntp_server.fqdn.value for ntp_server in entity.network.ntp_server_ip_list})
elif "ipv4" in entity.network.ntp_server_ip_list:
entity_output['ntp_server_list'] = list({ ntp_server.ipv4.value for ntp_server in entity.network.ntp_server_ip_list})
cluster_list_output.append(entity_output)
#endregion #?clustersAn entity type region does:
- set up the SDK API client
- use multithreading with the fetch_entities function to get all entities
- build a variable keeping the object properties we’re interested to include in our final output
1 and 2 were already pretty much covered in part 1 of this series, but let’s go over it again.
To create API client objects, we need to specify a configuration. This is achieved with:
api_client_configuration = ntnx_clustermgmt_py_client.Configuration()
api_client_configuration.host = api_server
api_client_configuration.username = username
api_client_configuration.password = secretNote how we use parameters passed to the main function which were themselves captured from the parsed script command line to populate values in the API client configuration. api_server is in fact args.prism, username is args.username and secret is pwd, which we retrieved from our credential vault. We decided all of this in our unnamed section with that line we used to call our main function:
main(api_server=args.prism,username=args.username,secret=pwd,secure=args.secure)We then make sure to suppress annoying stdout warnings when we’re not validating SSL certs with:
if secure is False:
#! suppress warnings about insecure connections
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
#! suppress ssl certs verification
api_client_configuration.verify_ssl = FalseTo fetch entities, the next code section starts by creating an API client with this configuration and then creates an API entity object:
client = ntnx_clustermgmt_py_client.ApiClient(configuration=api_client_configuration)
entity_api = ntnx_clustermgmt_py_client.ClustersApi(api_client=client)We then initialize a list variable we’ll use to populate results:
entity_list=[]We then need to retrieve the total number of entities available by making a quick call with a single object:
response = entity_api.list_clusters(_page=0,_limit=1)
total_available_results=response.metadata.total_available_results
page_count = math.ceil(total_available_results/limit)We now know how many pages of results exist in the API with the limit that we are using and we can use this to start a multi-threaded retrieval that includes a nice progress bar:
with tqdm.tqdm(total=page_count, desc="Fetching entity pages") as progress_bar:
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(
fetch_entities,
module=ntnx_clustermgmt_py_client,
entity_api='ClustersApi',
client=client,
function='list_clusters',
page=page_number,
limit=limit
) for page_number in range(0, page_count, 1)]
for future in as_completed(futures):
try:
entities = future.result()
entity_list.extend(entities.data)
except Exception as e:
print(f"{PrintColors.WARNING}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [WARNING] Task failed: {e}{PrintColors.RESET}")
finally:
progress_bar.update(1)Note that when each call succeeds, we append results to our list variable with:
entity_list.extend(entities.data)…and we update our progress bar with:
progress_bar.update(1)After this is all done, we save our results in a variable:
cluster_list = entity_listNow we need the process this output and keep only what we want to report on. To do this, we start by initializing a list variable with:
cluster_list_output = []We then have a loop to look at each individual result from our multi-threaded retrieval and extract only the information we need:
for entity in cluster_list:
if 'PRISM_CENTRAL' in entity.config.cluster_function:
continue
entity_output = {
'name': entity.name,
'ext_id': entity.ext_id,
'incarnation_id': entity.config.incarnation_id,
'is_available': entity.config.is_available,
'operation_mode': entity.config.operation_mode,
'redundancy_factor': entity.config.redundancy_factor,
'domain_awareness_level': entity.config.fault_tolerance_state.domain_awareness_level,
'current_max_fault_tolerance': entity.config.fault_tolerance_state.current_max_fault_tolerance,
'desired_max_fault_tolerance': entity.config.fault_tolerance_state.desired_max_fault_tolerance,
'upgrade_status': entity.upgrade_status,
'vm_count': entity.vm_count,
'inefficient_vm_count': entity.inefficient_vm_count,
'cluster_arch': entity.config.cluster_arch,
'cluster_function': entity.config.cluster_function,
'hypervisor_types': entity.config.hypervisor_types,
'is_password_remote_login_enabled': entity.config.is_password_remote_login_enabled,
'is_remote_support_enabled': entity.config.is_remote_support_enabled,
'pulse_enabled': entity.config.pulse_status.is_enabled,
'timezone': entity.config.timezone,
'ncc_version': next(iter({ software.version for software in entity.config.cluster_software_map if software.software_type == "NCC" })),
'aos_full_version': entity.config.build_info.full_version,
'aos_commit_id': entity.config.build_info.short_commit_id,
'aos_version': entity.config.build_info.version,
'is_segmentation_enabled': entity.network.backplane.is_segmentation_enabled,
'external_address_ipv4': entity.network.external_address.ipv4.value,
'external_data_service_ipv4': entity.network.external_data_service_ip.ipv4.value,
'external_subnet': entity.network.external_subnet,
'name_server_ipv4_list': list({ name_server.ipv4.value for name_server in entity.network.name_server_ip_list}),
'ntp_server_list': "",
'number_of_nodes': entity.nodes.number_of_nodes,
}
if "fqdn" in entity.network.ntp_server_ip_list:
entity_output['ntp_server_list'] = list({ ntp_server.fqdn.value for ntp_server in entity.network.ntp_server_ip_list})
elif "ipv4" in entity.network.ntp_server_ip_list:
entity_output['ntp_server_list'] = list({ ntp_server.ipv4.value for ntp_server in entity.network.ntp_server_ip_list})
cluster_list_output.append(entity_output)Note that:
- we skip the result if it points at Prism Central itself (which is just an oddity of the Nutanix cluster API).
- to figure out property names on the API returned entity, use the documentation
- some properties are lists which can have various shapes of forms and that will required logic to figure out, such as
ntp_server_ip_listin the above example (which can contain either IPv4 addresses or fully qualified domain names).
In the end, everything is stored in the cluster_list_output variable which we will use later.
Whether we’re looking at clusters, vms, users, categories, the logic and flow will be the same. Have a look at the entire script to see this.
html report
Here is the region that produces the html report:
#region #?html report
#* exporting to html
html_file_name = f"{api_server}_get_pc_report.html"
print(f"{PrintColors.OK}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [INFO] Exporting results to file {html_file_name}.{PrintColors.RESET}")
vm_df = pd.DataFrame(vm_list_output)
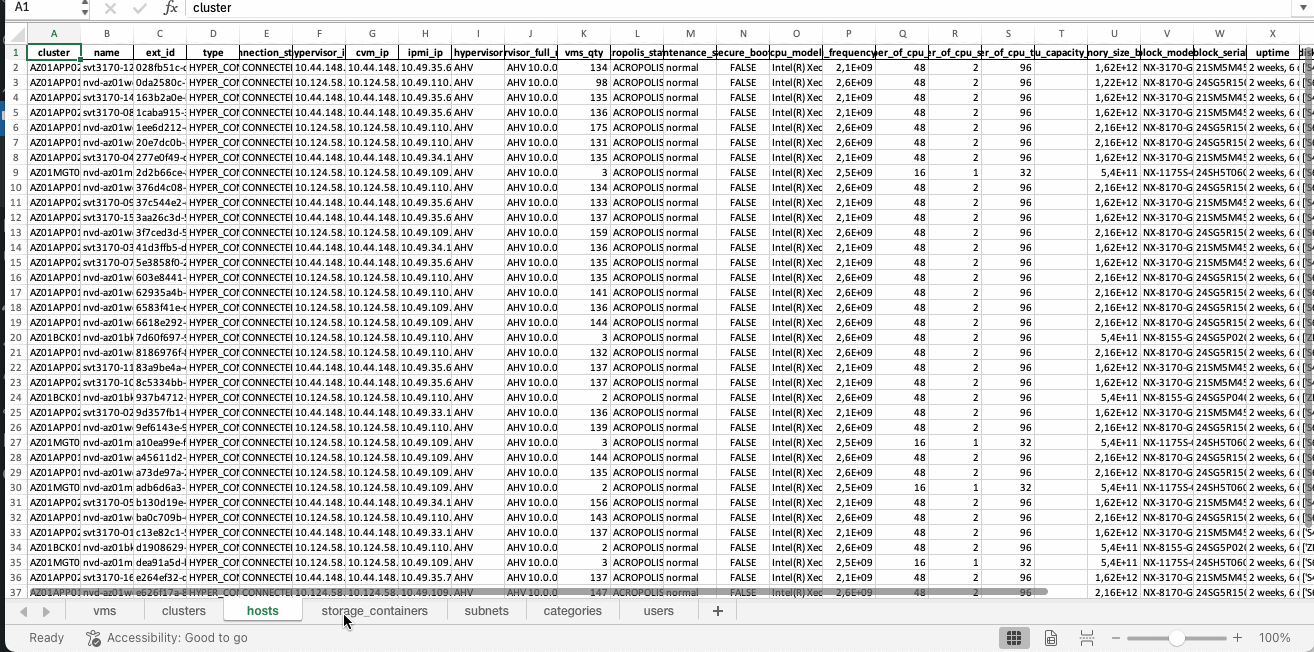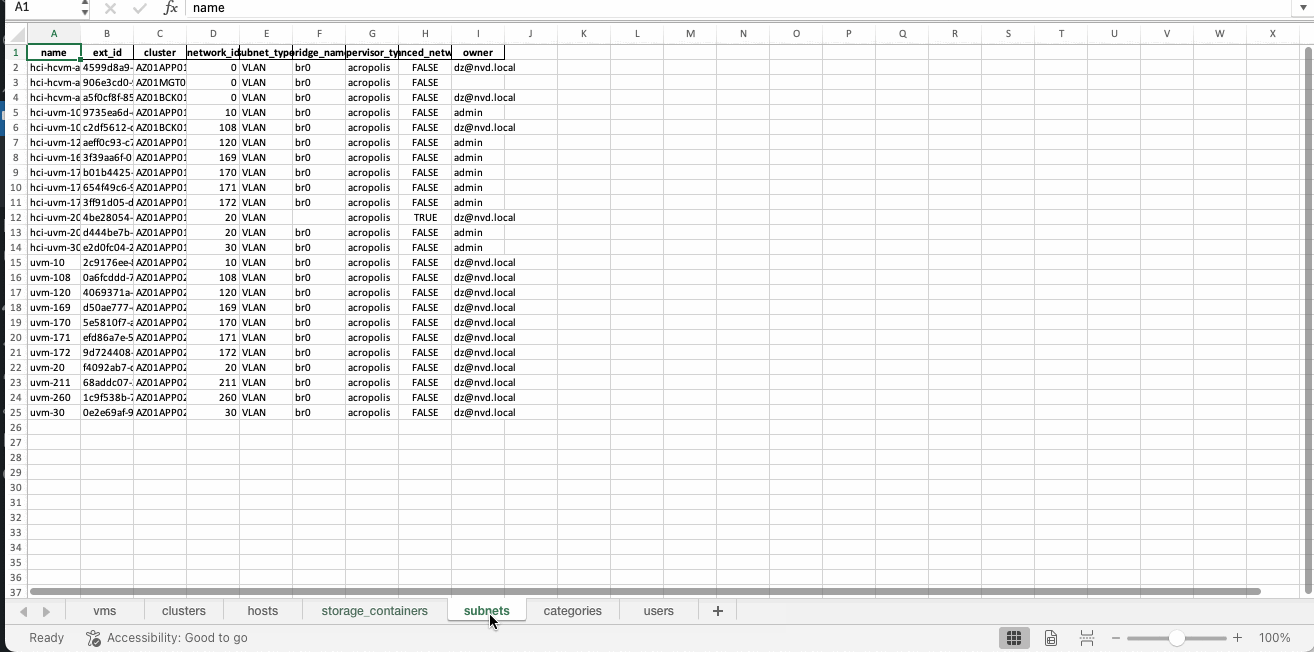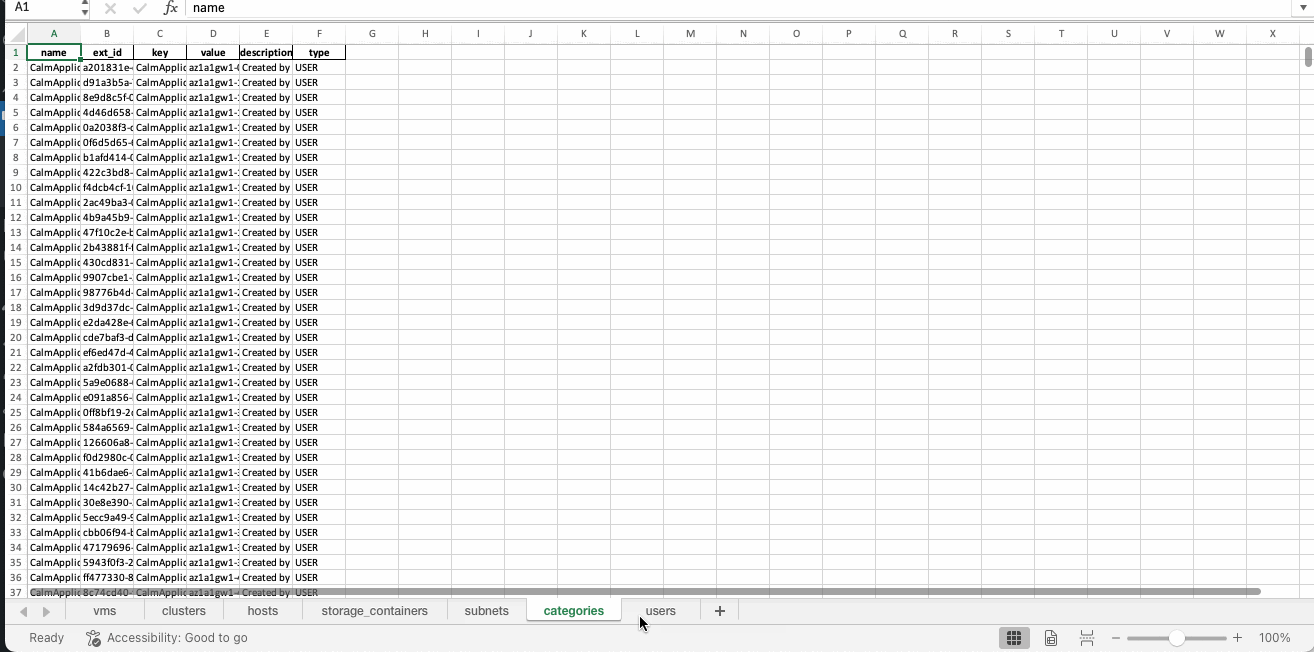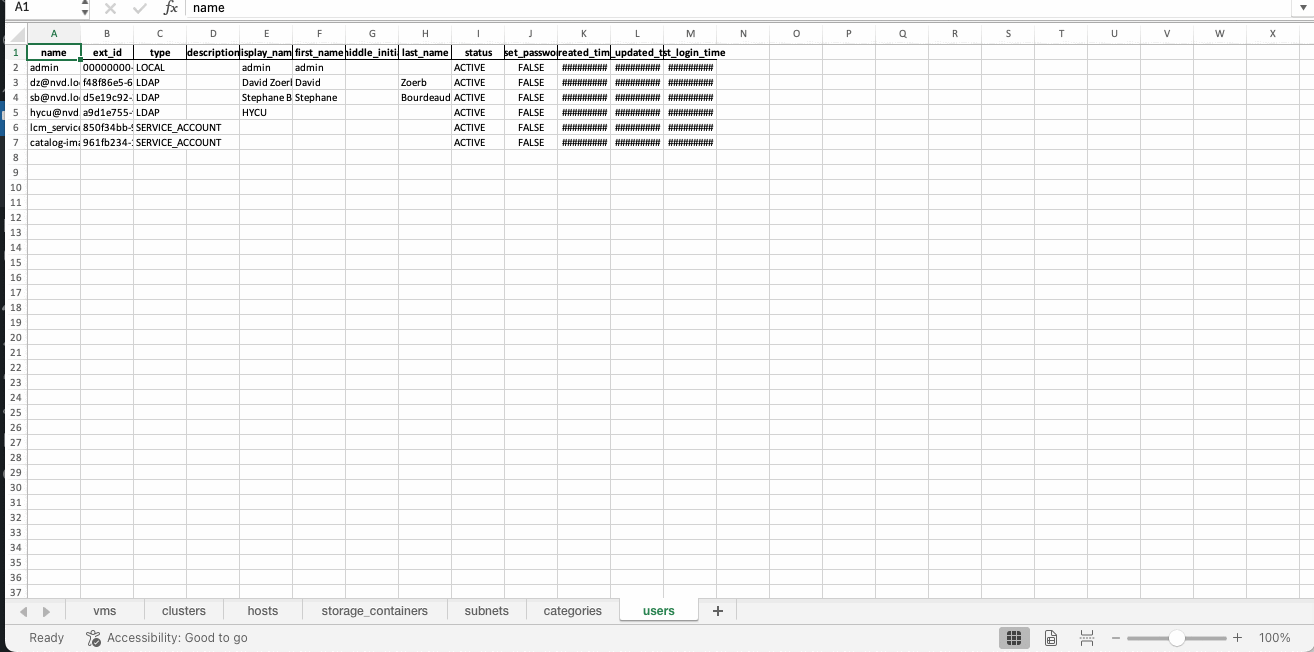
cluster_df = pd.DataFrame(cluster_list_output)
host_df = pd.DataFrame(host_list_output)
storage_container_df = pd.DataFrame(storage_container_list_output)
subnet_df = pd.DataFrame(subnet_list_output)
category_df = pd.DataFrame(category_list_output)
user_df = pd.DataFrame(user_list_output)
datapane_app = datapane.App(
datapane.Select(
datapane.DataTable(vm_df,label="vms"),
datapane.DataTable(cluster_df,label="clusters"),
datapane.DataTable(host_df,label="hosts"),
datapane.DataTable(storage_container_df,label="storage_containers"),
datapane.DataTable(subnet_df,label="subnets"),
datapane.DataTable(category_df,label="categories"),
datapane.DataTable(user_df,label="users"),
)
)
datapane_app.save(html_file_name)
#endregion #?html reportHere we:
- decide what we’re going to call our final html report file,
- create pandas dataframes with our output variables (because this is what datapane takes as input to create dynamic tables in html format),
- use those dataframes to feed a datapane app with multiple pages (one per entity type), then save that app to the html file we defined in step 1.
excel spreadsheet
Here is the region that creates our Excel spreadsheet output:
#region #?excel spreadsheet
excel_file_name = f"{api_server}_get_pc_report.xlsx"
print(f"{PrintColors.OK}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [INFO] Exporting results to file {excel_file_name}.{PrintColors.RESET}")
data = {'vms': vm_list_output, 'clusters': cluster_list_output, 'hosts': host_list_output, 'storage_containers': storage_container_list_output, 'subnets': subnet_list_output, 'categories': category_list_output, 'users': user_list_output}
with pd.ExcelWriter(excel_file_name, engine='xlsxwriter') as writer:
for sheet_name, df_data in data.items():
df = pd.DataFrame(df_data) # Create a DataFrame for each dictionary
if sheet_name == 'users':
df['created_time'] = df['created_time'].dt.tz_localize(None)
df['last_updated_time'] = df['last_updated_time'].dt.tz_localize(None)
df['last_login_time'] = df['last_login_time'].dt.tz_localize(None)
df.to_excel(writer, sheet_name=sheet_name, index=False) # index=False to avoid row numbers
#endregion #?excel spreadsheetHere we:
- define the name of the final Excel spreadsheet file,
- define the structure of our spreadsheet (which worksheets our workbook will have, and what they’ll contain),
- write the content of the spreadsheet, making sure we transform timestamps into localized data which Excel requires for the users worksheet.
And voilà!
Wait, we finish our script by showing total processing time with:
end_time = time.time()
elapsed_time = end_time - start_time
print(f"{PrintColors.STEP}{(datetime.datetime.now()).strftime('%Y-%m-%d %H:%M:%S')} [SUM] Process completed in {format_timespan(elapsed_time)}{PrintColors.RESET}")Wrapping up
This is what the execution of the script looks like:
This is what the html report looks like:
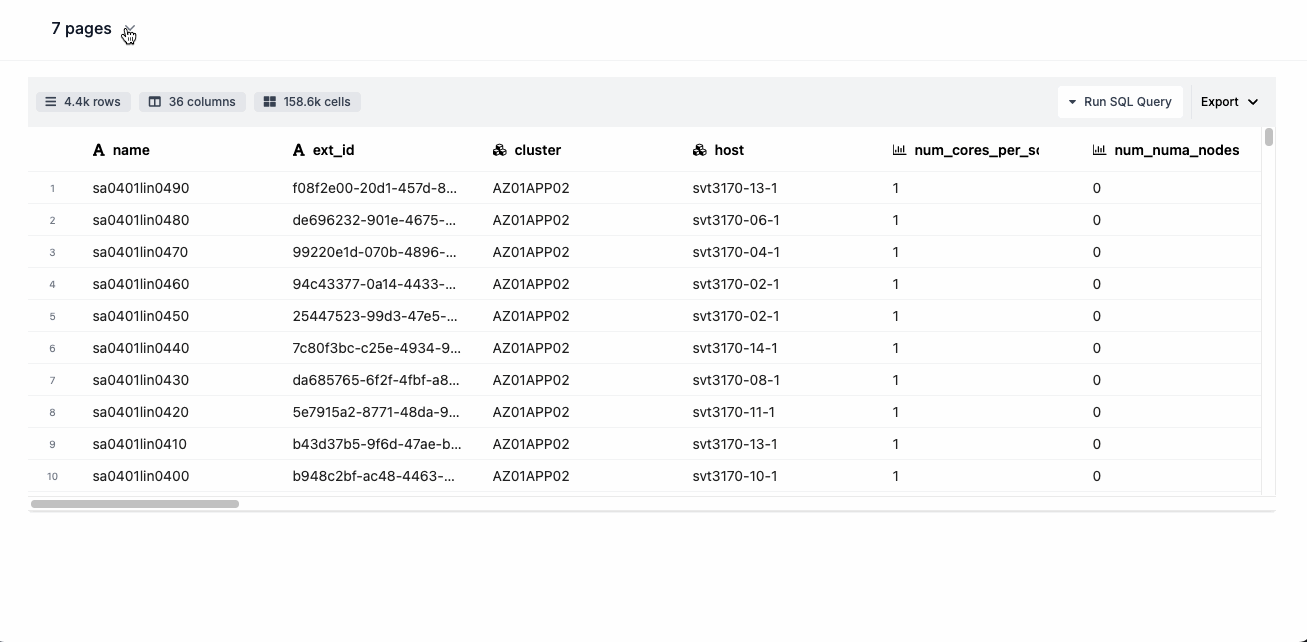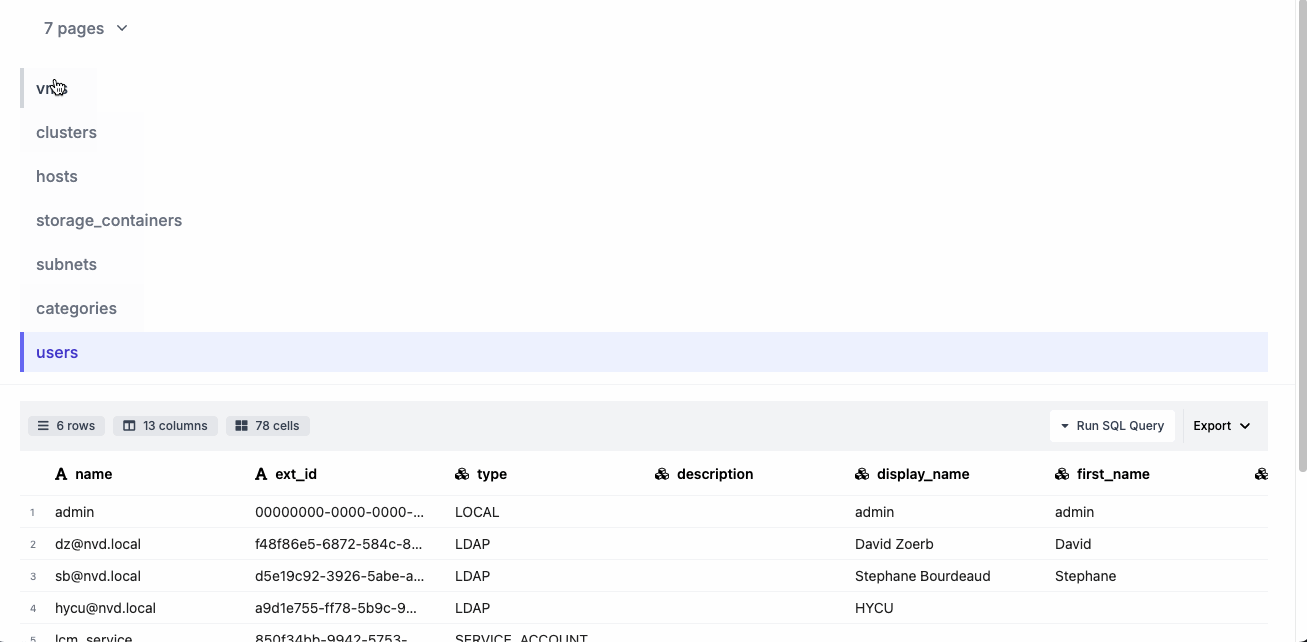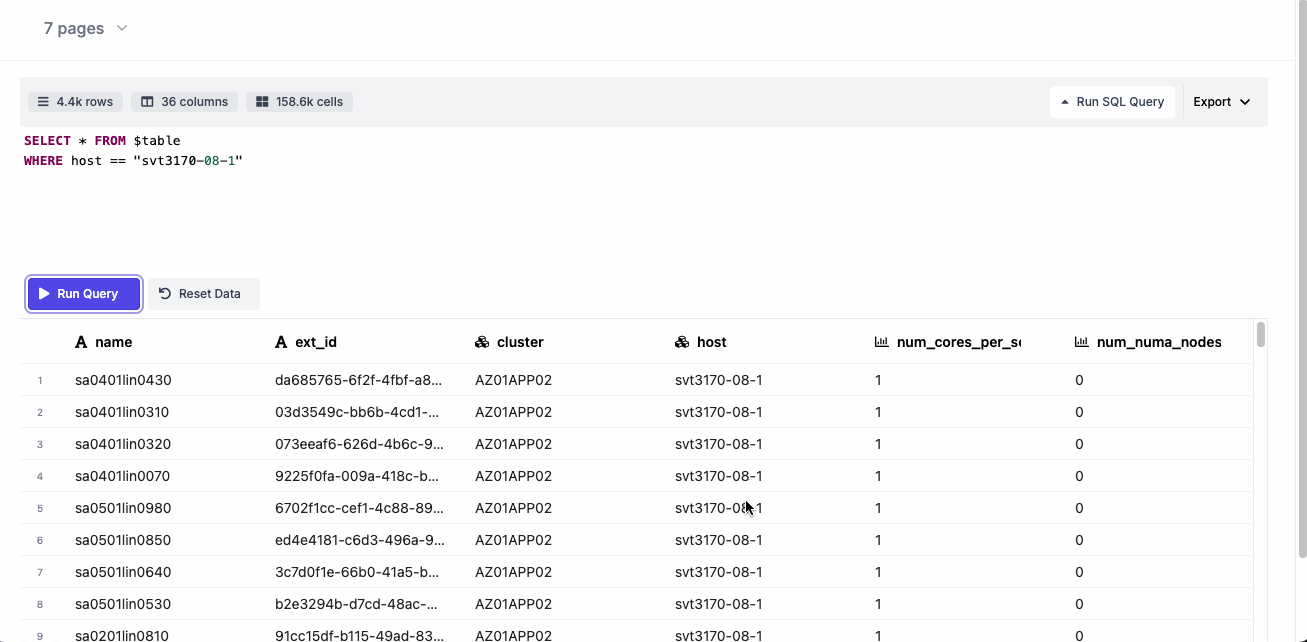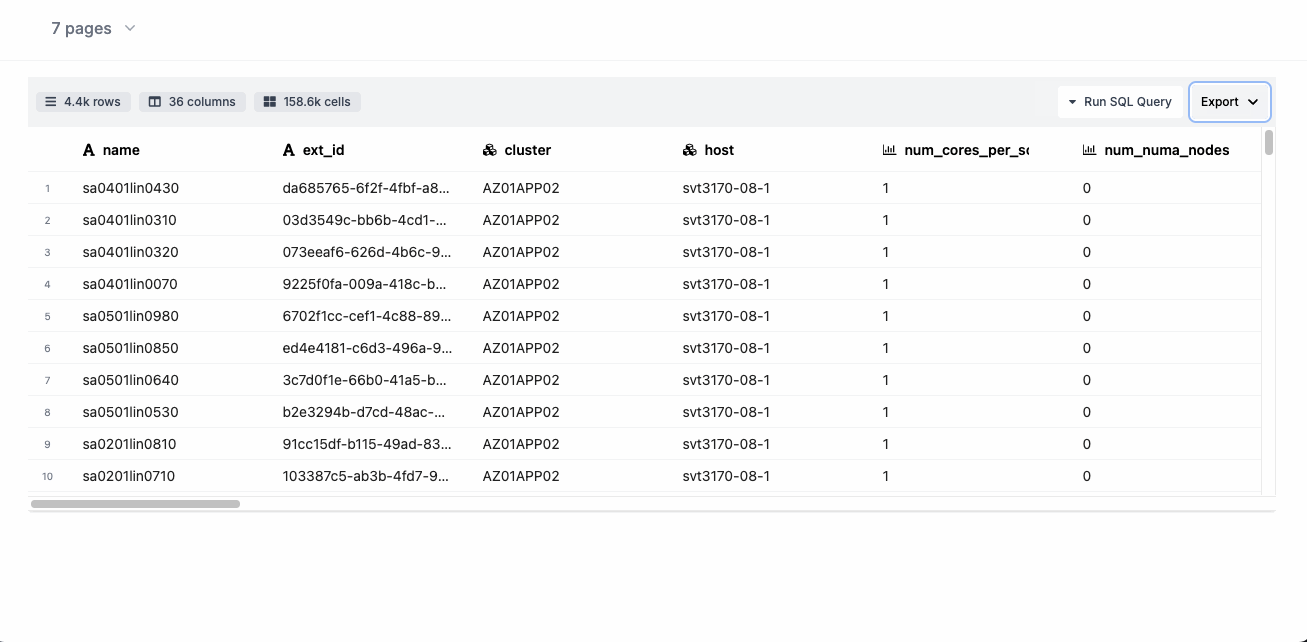
This is what the Excel report looks like:
The entire script can be downloaded here.
Thanks for reading. That’s all folks!